Manuel utilisateur anonym.plus
Aperçu
anonym.plus Desktop est une application sécurisée d'anonymisation de documents qui détecte et supprime les Données Personnelles Identifiables (DPI) des documents et images. Il utilise un moteur de détection de DPI local (Presidio) et un coffre-fort chiffré pour le stockage sécurisé.
Voir en action : Regardez nos 36 vidéos tutorielles couvrant chaque fonctionnalité en 4 langues.
Avantages clés
- Moteur de détection de DPI local — aucun cloud requis pour l'analyse
- Chiffrement de qualité militaire (AES-256-GCM) pour les données stockées
- Chiffrement réversible — chiffrez les DPI, partagez les documents, déchiffrez plus tard
- Support pour PDF, DOCX, XLSX, TXT, CSV, JSON, XML et images (PNG, JPG, BMP, TIFF)
- Plus de 200 types d'entités DPI dans toutes les régions mondiales
- 121 présets de détection intégrés (RGPD, HIPAA, Financial, Regional, etc.)
- Détection personnalisée d'entités via des motifs regex
- 48 langues supportées
- Traitement par lots avec gestion parallèle des fichiers
- Multiplateforme : Windows, macOS, Linux
Configuration requise
| Plateforme | Exigence |
|---|---|
| Windows | Windows 10 ou ultérieur (x64) |
| macOS | macOS 10.15 (Catalina) ou ultérieur |
| Linux | Ubuntu 20.04+, Debian 11+, ou équivalent |
| Mémoire | 4 Go de RAM minimum, 8 Go recommandés |
| Stockage | 500 Mo pour l'installation |
Installation
Windows
| Format | Instructions |
|---|---|
| .exe (NSIS) | Téléchargez et exécutez le programme d'installation .exe pour l'installation standard |
| .msi | Téléchargez et exécutez l'installateur .msi pour le déploiement en entreprise |
| .zip (Portable) | Téléchargez le .zip portable et extrayez — aucune installation requise |
macOS
Téléchargez le fichier .dmg, ouvrez-le et faites glisser l'application dans Applications.
Linux
| Format | Instructions |
|---|---|
| .deb | sudo dpkg -i anonym.plus_*.deb |
| .AppImage | Rendez exécutable : chmod +x, puis exécutez |
Premier lancement
Lors de votre première ouverture d'anonym.plus, un assistant de configuration guidé vous accompagne à travers cinq étapes : choisir comment commencer, créer votre coffre-fort sécurisé, définir un PIN, activer votre licence et sélectionner un dossier de sortie. Chaque étape est expliquée ci-dessous avec des captures d'écran.
Étape 1 : Écran de bienvenue
L'écran de bienvenue présente trois options pour commencer :
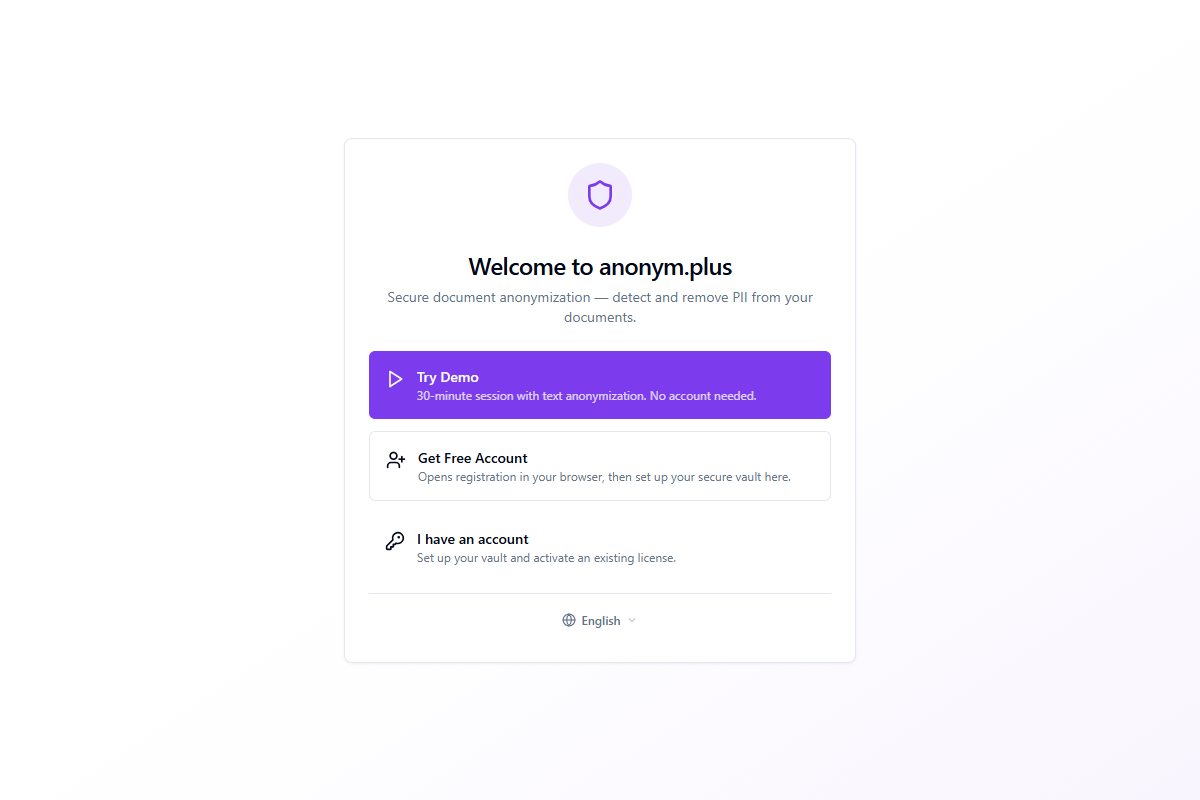
| Option | Description |
|---|---|
| Essai gratuit | Commencez une session de démonstration de 30 minutes avec anonymisation de texte. Aucun compte requis — idéal pour un test rapide. |
| Créer un compte gratuit | Ouvre l'inscription dans votre navigateur, puis revient pour configurer votre coffre-fort sécurisé. |
| J'ai un compte | Configurez votre coffre-fort et activez une licence existante. |
Un sélecteur de langue en bas vous permet de changer la langue de l'interface avant de procéder. 48 langues sont disponibles.
Étape 2 : Phrase de récupération et création de coffre-fort
Après avoir choisi « Créer un compte gratuit » ou « J'ai un compte », l'application génère un coffre-fort sécurisé protégé par une phrase de récupération BIP39 de 24 mots. Cette phrase est la clé principale de votre coffre-fort.
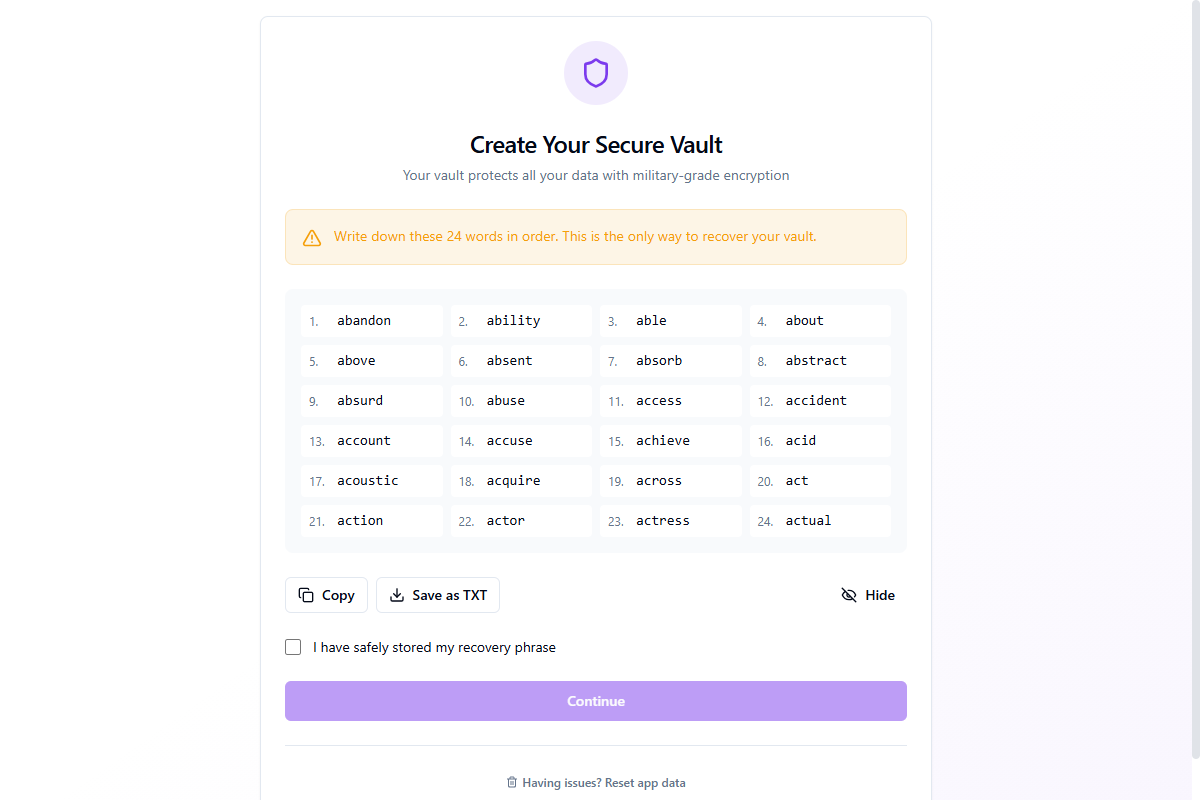
Vous pouvez Copier la phrase dans le presse-papiers (automatiquement effacée après 30 secondes) ou Enregistrer en TXT dans un fichier. Cliquez sur Masquer pour flouter les mots pour la confidentialité. Vous devez cocher « J'ai stocké en toute sécurité ma phrase de récupération » avant de continuer.
Vérifier votre phrase
Pour confirmer que vous avez sauvegardé la phrase correctement, l'application vous demande d'entrer 3 mots sélectionnés aléatoirement par leur numéro de position.
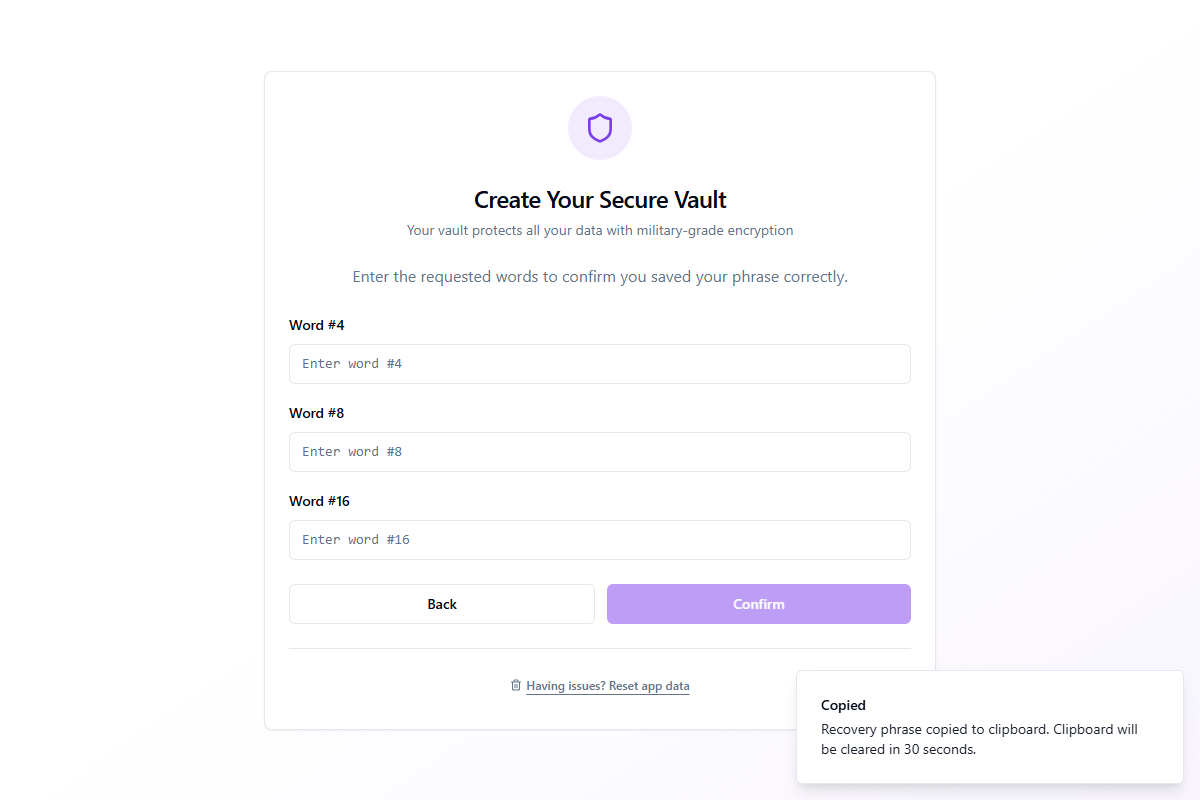
Tapez les mots corrects et cliquez sur Confirmer. Si un mot est incorrect, vous serez invité à réessayer. Une fois vérifié, le coffre-fort est créé et vous passez à la configuration du PIN.
Étape 3 : Configuration du PIN
Après la création du coffre-fort, vous pouvez définir un PIN de 4 à 8 chiffres pour un accès quotidien rapide. Le PIN vous permet de déverrouiller l'application sans taper les 24 mots à chaque fois.
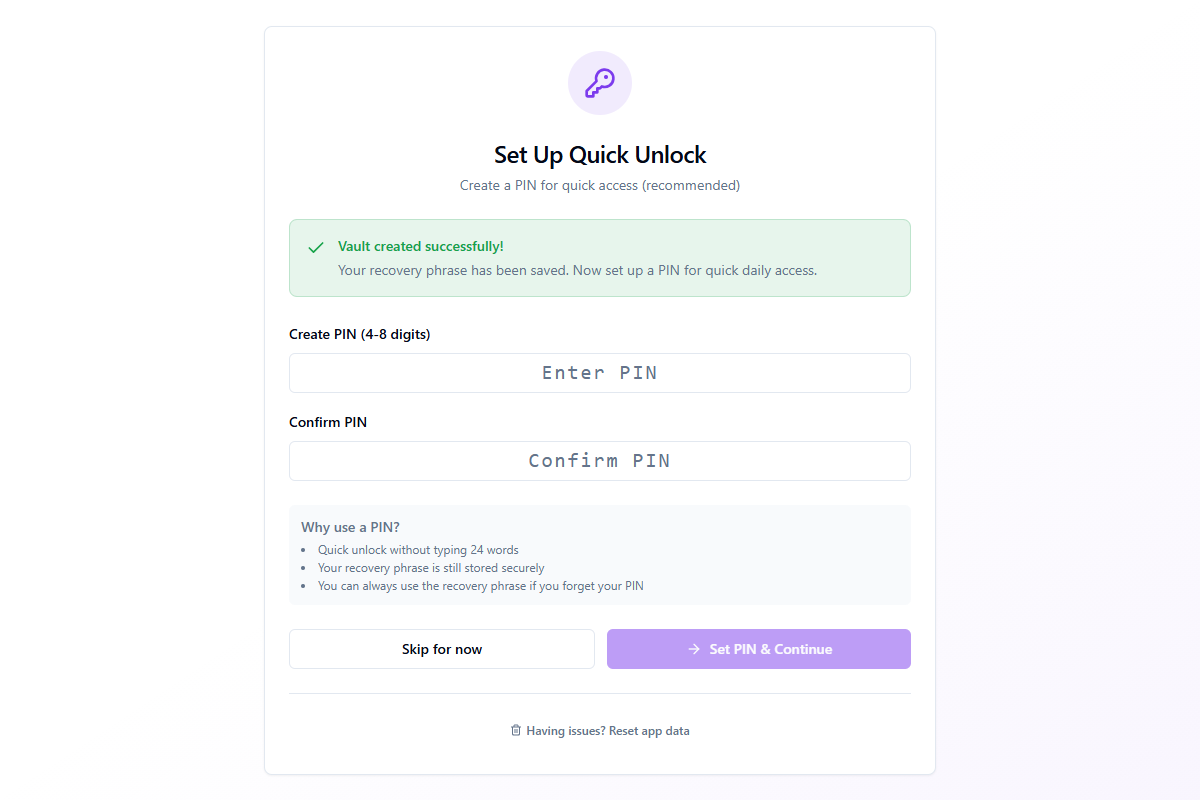
- Déverrouillage rapide sans taper votre phrase de récupération complète de 24 mots
- Votre phrase de récupération reste stockée de manière sécurisée dans le coffre-fort
- Vous pouvez toujours utiliser la phrase de récupération si vous oubliez votre PIN
Entrez votre PIN dans les deux champs et cliquez sur Définir le PIN et continuer. Vous pouvez également cliquer sur Ignorer pour l'instant pour définir un PIN plus tard dans Paramètres → Sécurité.
Étape 4 : Activation de la licence
Avec votre coffre-fort prêt, l'étape de sécurité finale consiste à activer votre licence anonym.plus pour déverrouiller toutes les fonctionnalités.
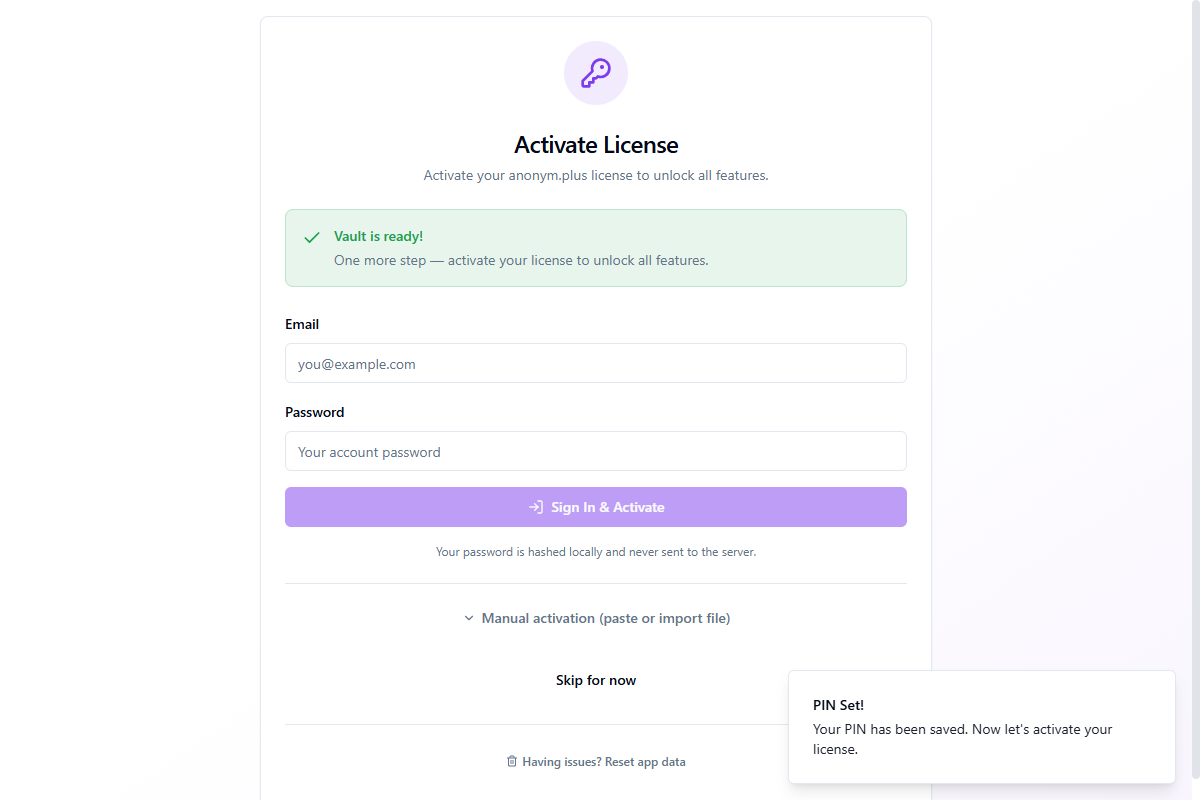
Entrez votre email et mot de passe, puis cliquez sur Se connecter et activer. Votre mot de passe est haché localement et jamais envoyé au serveur en texte clair.
Activation manuelle
Si la connexion ne fonctionne pas (par exemple, derrière un pare-feu d'entreprise), développez Activation manuelle (coller ou importer un fichier) pour des méthodes alternatives :
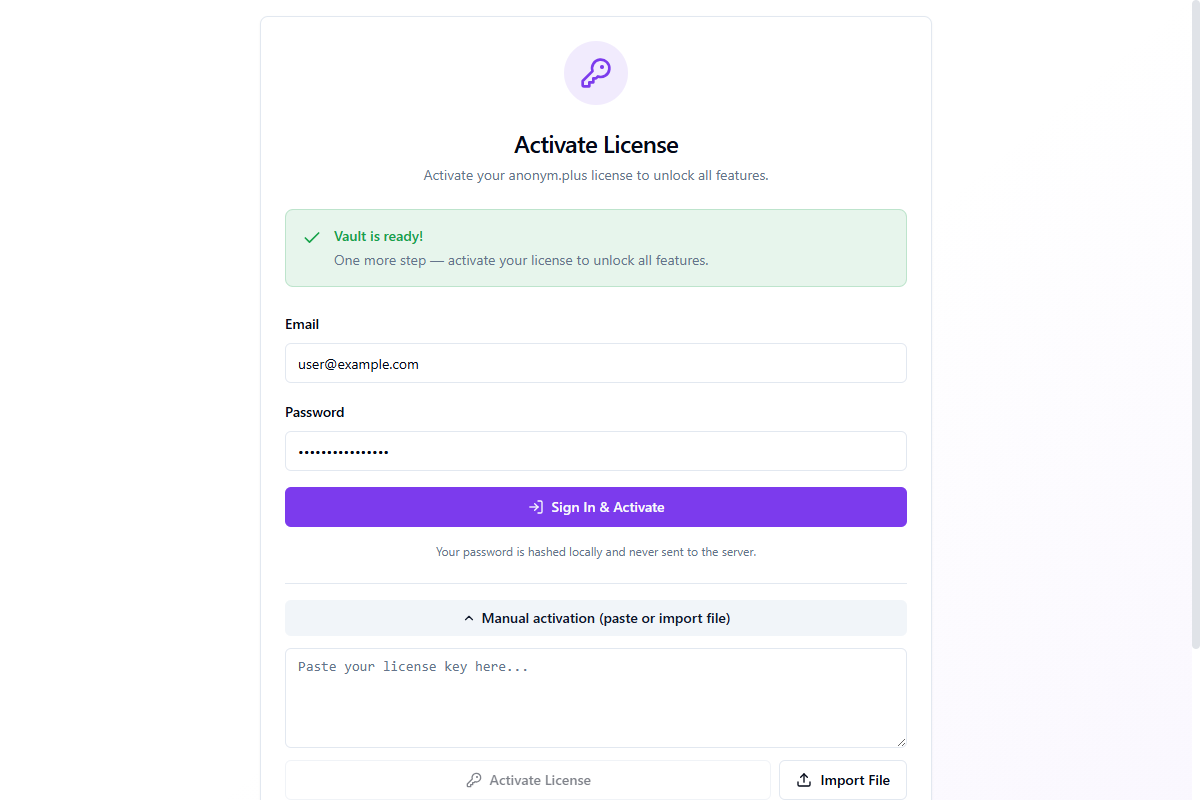
- Coller la clé de licence — collez la clé de licence JSON à partir de votre page de compte
- Importer un fichier — importez un fichier de licence
.jsontéléchargé depuis votre compte
Vous pouvez également cliquer sur Ignorer pour l'instant pour activer plus tard via Paramètres → Compte.
Étape 5 : Dossier de sortie
La dernière étape vous permet de choisir où les documents anonymisés seront enregistrés.
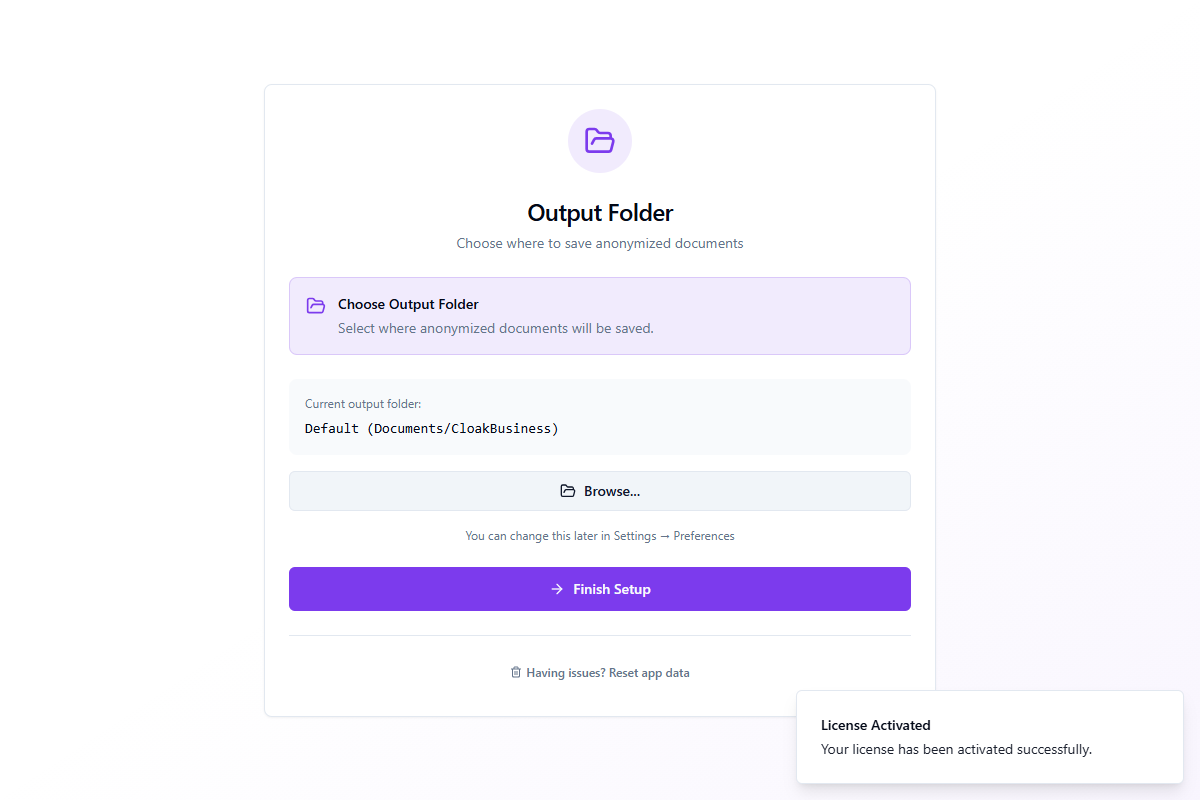
Le dossier par défaut est Documents/CloakBusiness. Cliquez sur Parcourir... pour sélectionner un emplacement différent. Vous pouvez changer cela plus tard dans Paramètres → Préférences.
Cliquez sur Terminer la configuration pour terminer l'assistant et accéder à l'application principale.
Aperçu de l'interface principale
Après la configuration, l'interface principale est organisée en plusieurs zones clés :
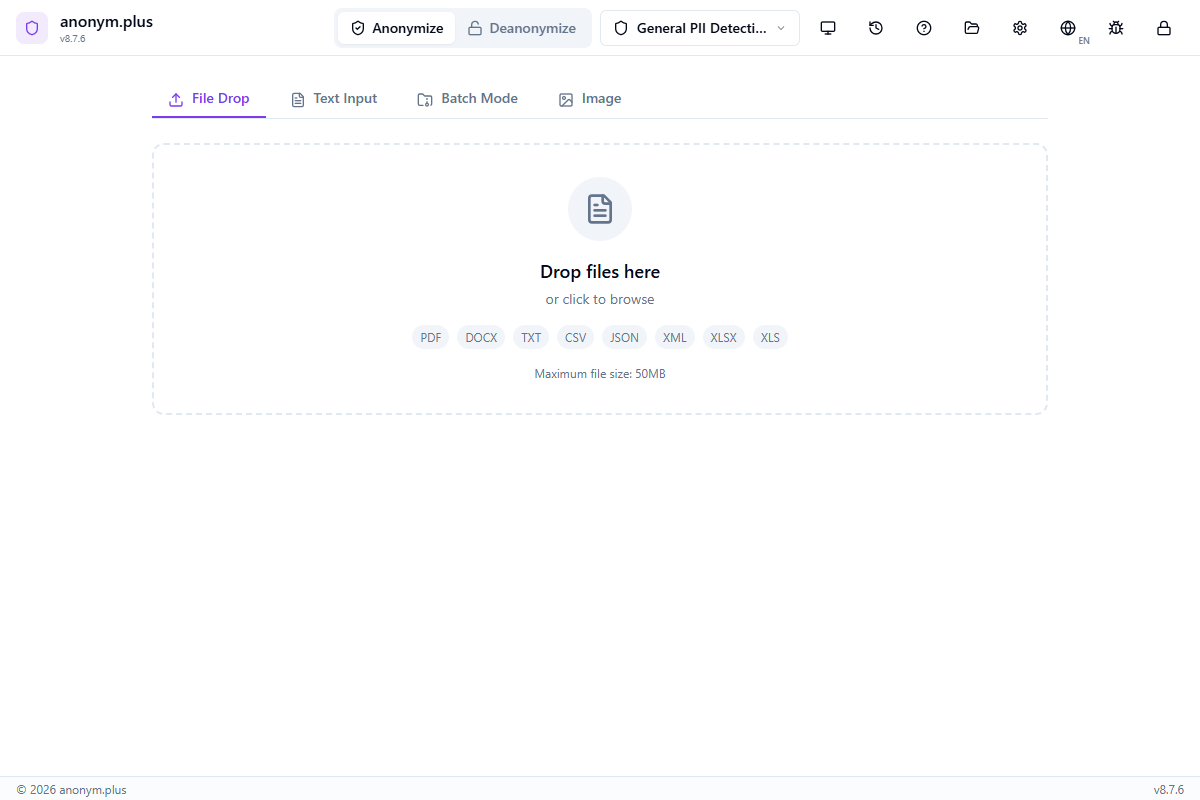
Barre de titre
- Basculement de mode — basculez entre les modes Anonymiser et Désanonymiser
- Sélecteur de préset — basculez rapidement entre les présets de détection
- Historique — ouvrez le panneau d'historique de traitement
- Paramètres — accédez aux paramètres de l'application (Ctrl + ,)
- Aide — ouvrez le panneau d'aide dans l'application (F1)
- Signaler un bug — signalez les problèmes avec les informations de diagnostic
Zone de traitement
- Zone de glissement de fichier — glissez-déposez les fichiers ou cliquez pour parcourir. Prend en charge les fichiers uniques et les téléchargements par lots.
- Onglet Document / Image — basculez entre le mode d'anonymisation de texte de document et le mode de rédaction d'image
- Panneau de résultats — affiche les entités détectées groupées par type avec les contrôles d'acceptation/rejet
- Options de sortie — choisissez le format de sortie et l'emplacement d'enregistrement
Barre d'état
Le bas de la fenêtre affiche l'état du moteur (en cours d'exécution/arrêté) et la clé de chiffrement actuellement active.
Anonymisation de documents
La fonctionnalité principale — détectez et anonymisez les informations personnelles dans les documents.
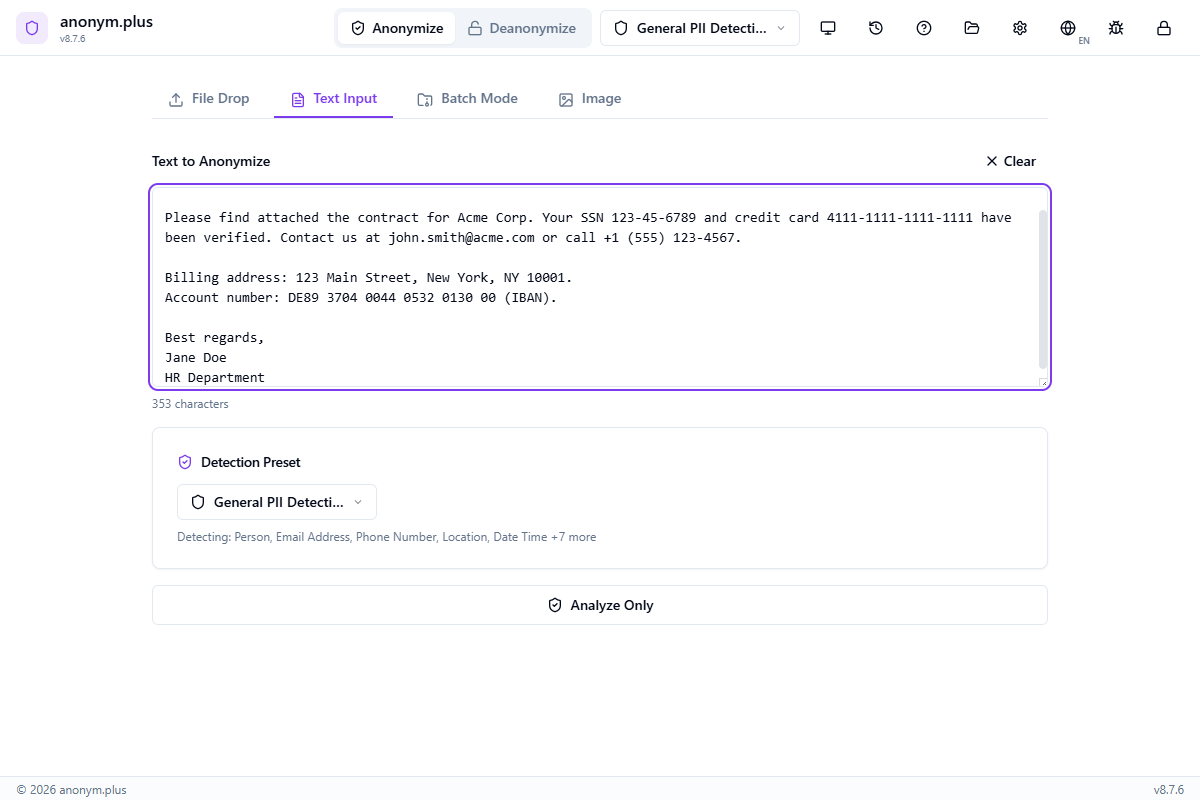
Flux de travail
Glissez-déposez les fichiers sur la zone de glissement ou cliquez pour parcourir
Choisissez un préset de détection qui correspond à votre cas d'usage (RGPD, HIPAA, Financial, etc.)
Cliquez sur « Démarrer l'analyse » pour extraire le texte et détecter les entités
Examinez les entités détectées groupées par type (noms, emails, téléphones, etc.)
Sélectionnez le format de sortie (identique, PDF, DOCX, TXT) et l'option d'enregistrement
Cliquez sur « Enregistrer en tant que nouveau fichier » ou « Remplacer l'original » pour terminer
Formats supportés
Entrée
Sortie
Limites de taille de fichier
| Format | Taille max |
|---|---|
| 50 Mo | |
| TXT | 50 Mo |
| DOCX | 30 Mo |
| CSV | 30 Mo |
| JSON | 30 Mo |
| XML | 30 Mo |
| XLSX | 20 Mo ou 100 000 lignes |
Anonymisation d'images
Détectez et rédactionnez les informations personnelles directement dans les images. Utilise OCR Tesseract pour extraire le texte des images, puis applique le même moteur de détection de DPI pour trouver et rédactionner visuellement les données sensibles.
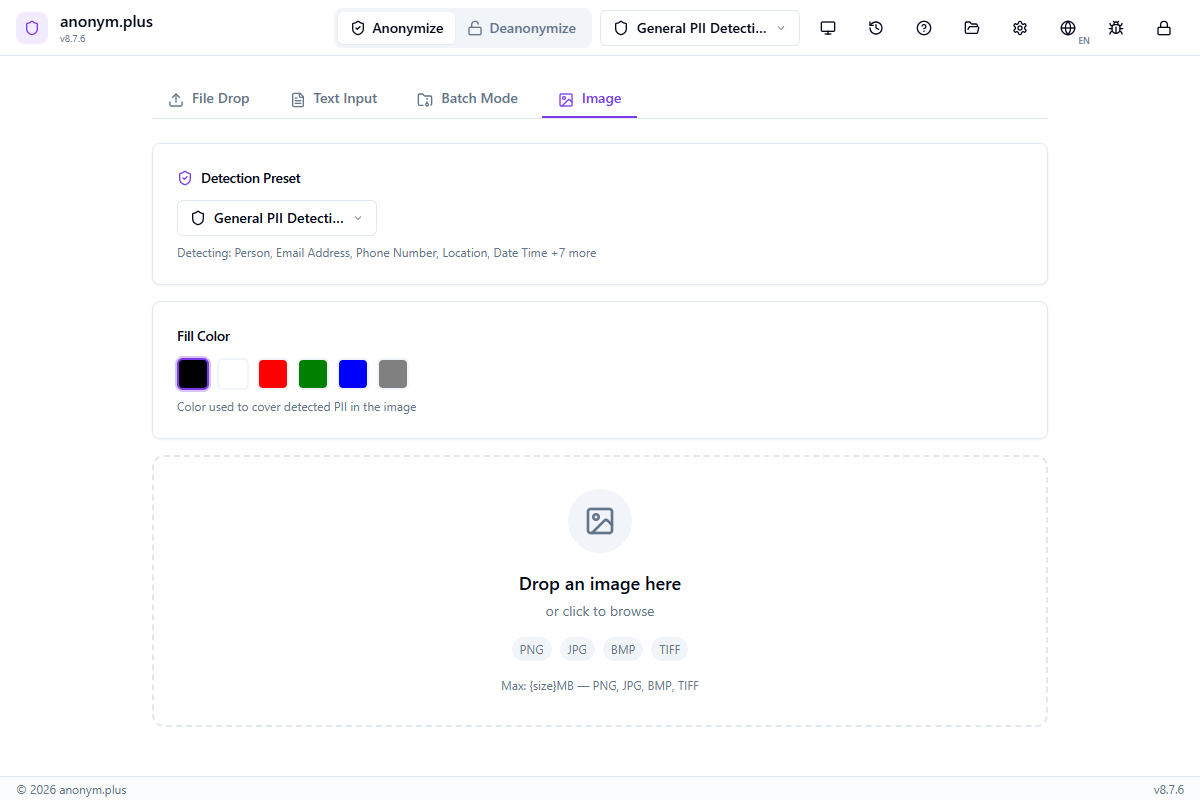
Flux de travail
Cliquez sur l'onglet Image dans le panneau d'anonymisation
Glissez-déposez un fichier image (PNG, JPG, BMP ou TIFF) ou cliquez pour parcourir. Max : 10 Mo, 25 mégapixels.
Choisissez un préset de détection et la langue OCR correspondant au texte de votre image
Cliquez sur « Analyser » pour extraire le texte via OCR et détecter les entités DPI avec des boîtes de délimitation
Cliquez sur « Rédactionner » pour générer une nouvelle image avec les DPI couverts par des boîtes de rédaction colorées
Téléchargez l'image rédactionnée en PNG
Formats supportés
Langues OCR
38 langues supportées incluant l'anglais, l'allemand, le français, l'espagnol, l'italien, le portugais, le néerlandais, l'arabe, le chinois, le japonais, le coréen, l'hindi, le russe et bien d'autres. Sélectionnez la langue correcte pour une meilleure précision OCR.
Fonctionnement
Limitations connues
| Problème | Détail |
|---|---|
| Photos d'écrans | Les motifs de moiré, l'éblouissement et les reflets dégradent l'OCR. Utilisez des captures d'écran à la place. |
| Texte manuscrit | Tesseract est optimisé uniquement pour le texte imprimé/dactylographié. |
| Basse résolution | En dessous de 150 PPP, la précision peut être faible. Utilisez 300+ PPP pour les numérisations. |
| Texte pivoté/déformé | Le texte à des angles > 15° peut ne pas s'extraire correctement. |
| Arrière-plans complexes | Les filigranes et les arrière-plans colorés peuvent interférer. |
| Très petit texte | En dessous d'environ 8pt à la résolution effective de l'image, peut ne pas être détecté. |
| Mises en page multi-colonnes | L'OCR peut mélanger les colonnes dans les mises en page complexes. |
| Langue NER | La reconnaissance d'entités nommées utilise le modèle anglais. Les entités basées sur des motifs (téléphones, IBANs, emails) fonctionnent dans toutes les langues. |
Conseils
- Utilisez des captures d'écran au lieu de photos d'écran pour de bien meilleurs résultats
- Sélectionnez la langue OCR correcte correspondant au texte de votre image
- Assurez-vous que les images sont bien éclairées avec un bon contraste entre le texte et l'arrière-plan
- Pour les documents numérisés, utilisez une résolution de 300 PPP ou supérieure
- Recadrez les images pour vous concentrer sur la zone de texte pour un traitement plus rapide
- L'orientation EXIF est appliquée automatiquement — pas besoin de faire pivoter manuellement les photos
Traitement par lots
Traitez plusieurs documents à la fois avec gestion parallèle des fichiers. Le mode par lots est disponible pour l'anonymisation de documents.
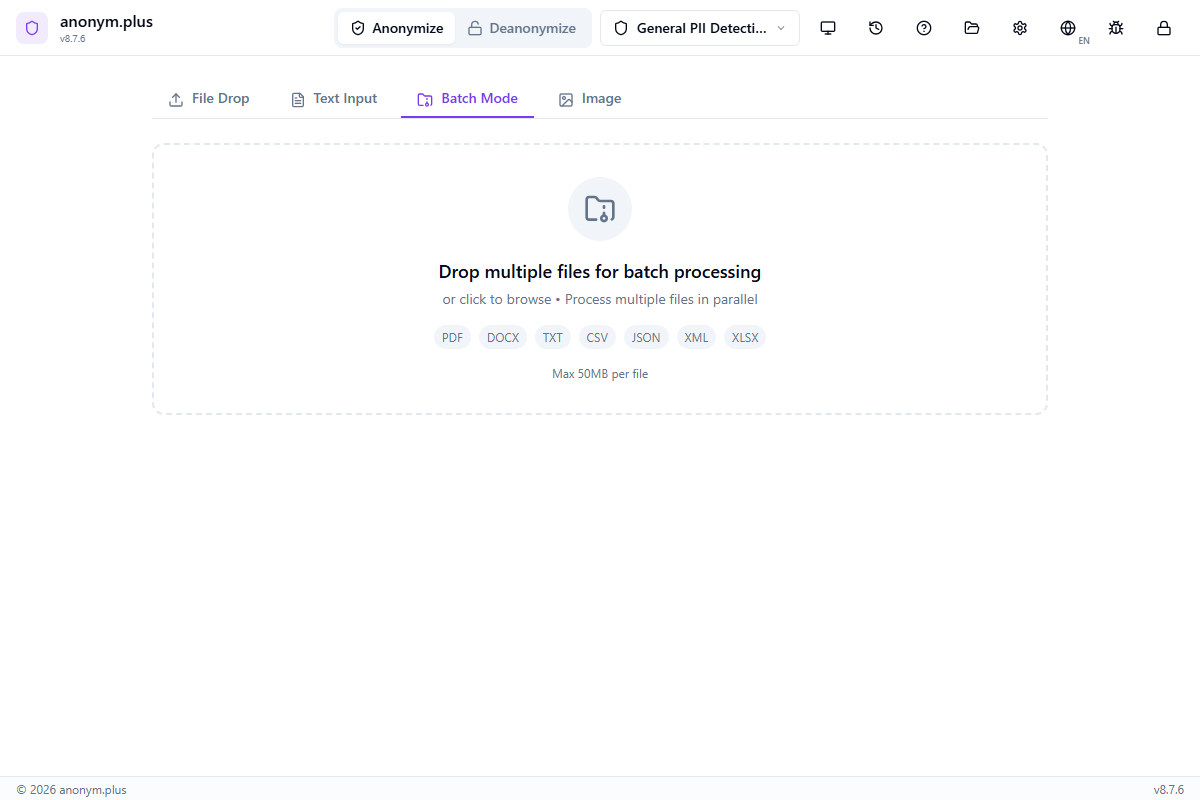
Flux de travail
Glissez-déposez jusqu'à 20 fichiers à la fois sur la zone de glissement ou cliquez pour parcourir et sélectionner plusieurs fichiers
Choisissez un préset de détection — le même préset s'applique à tous les fichiers du lot
Tous les fichiers sont extraits et analysés en parallèle pour un traitement plus rapide
Examinez les entités détectées pour chaque fichier individuellement — acceptez, rejetez ou modifiez les détections
Enregistrez tous les fichiers traités dans votre dossier de sortie
Limites
| Paramètre | Limite |
|---|---|
| Fichiers par lot | 20 |
| Taille totale du lot | Les limites de taille de fichier combinés s'appliquent par format (voir Anonymisation de documents) |
| Traitement parallèle | Les fichiers sont analysés simultanément pour la vitesse |
Suivi de la progression
Lors du traitement par lots, chaque fichier affiche son propre indicateur de progression avec l'état (en attente, extraction, analyse, terminé). Les fichiers qui échouent sont signalés individuellement sans arrêter le reste du lot.
Désanonymisation (Déchiffrement)
Restaurez les valeurs DPI d'origine des documents anonymisés en utilisant vos clés de chiffrement. Fonctionne avec tout document anonymisé à l'aide de l'opérateur « chiffrement ».
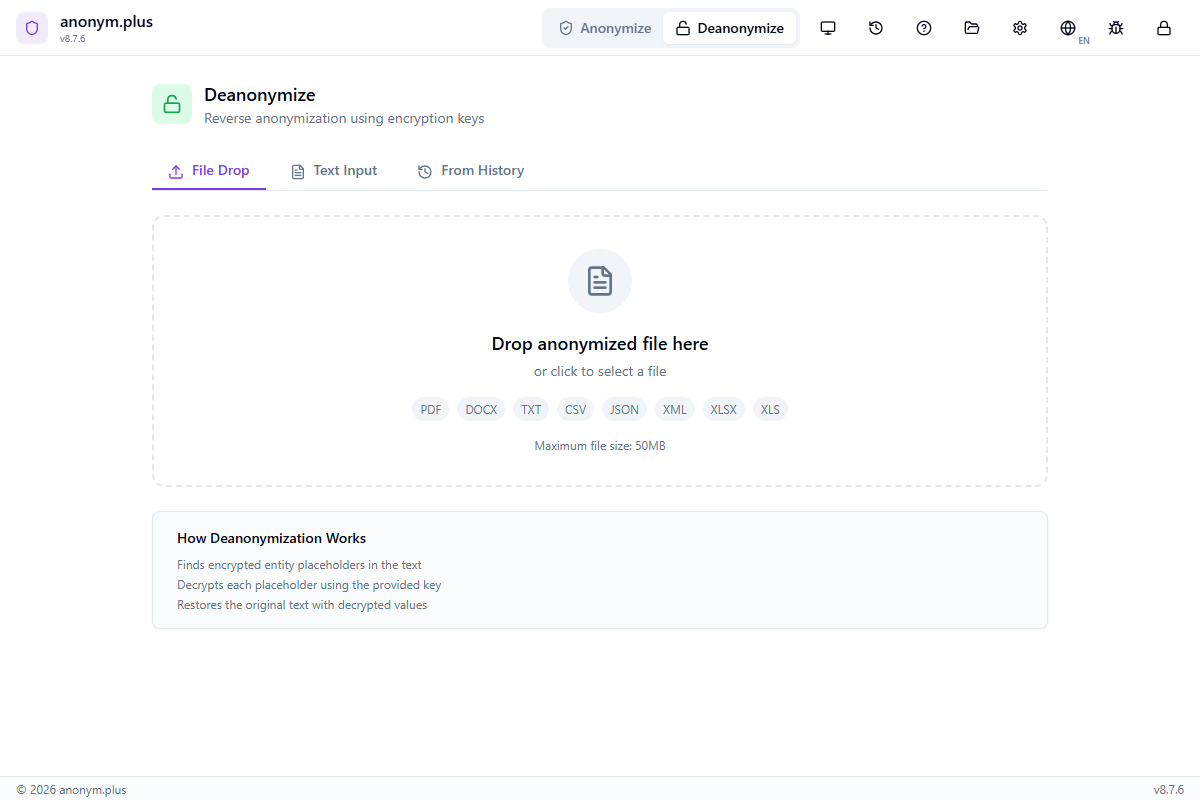
Modes d'entrée
Glissez-déposez un document anonymisé (PDF, DOCX, TXT, CSV, JSON, XML, XLSX). Le texte est extrait et automatiquement comparé à votre historique pour charger les clés de chiffrement correctes.
Collez le texte anonymisé directement. L'application recherche automatiquement votre historique pour les morceaux chiffrés correspondants et charge les clés correctes — même si le texte environnant a été modifié.
Sélectionnez une entrée d'anonymisation précédente. Toutes les positions d'entités et les mappages de clés sont chargés instantanément.
Comment désanonymiser
- Basculez en mode « Désanonymiser » à l'aide du basculement dans l'en-tête
- Glissez-déposez un fichier, collez du texte ou sélectionnez depuis l'historique — les clés se chargent automatiquement
- Si la correspondance automatique échoue, sélectionnez manuellement la clé de chiffrement
- Cliquez sur « Désanonymiser » pour restaurer les valeurs d'origine
- Copiez ou téléchargez le texte restauré
Chiffrer → Partager → Modifier → Déchiffrer
Vous pouvez chiffrer un document, le partager avec des collaborateurs, le recevoir avec des modifications et toujours déchiffrer les DPI :
Présets de détection
Profils de détection d'entités pré-configurés pour différents cas d'usage. 121 présets intégrés répartis sur 7 catégories.
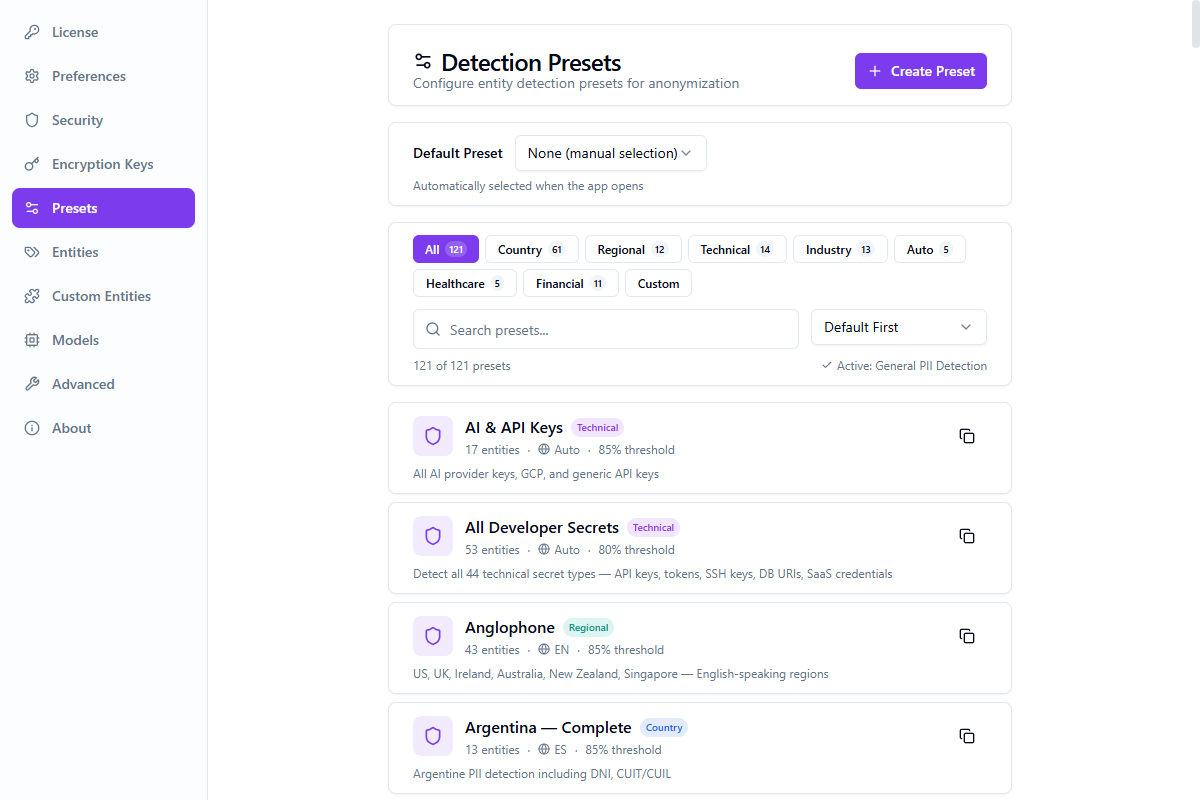
| Préset | Description | Seuil | Types d'entités |
|---|---|---|---|
| Détection générale de DPI | Détection complète pour les types de DPI courants | 0,85 | 10 |
| Conformité RGPD | Exigences européennes en matière de protection des données | 0,90 | 10 |
| Médical HIPAA | Protection des données de santé PHI aux États-Unis | 0,90 | 9 |
| Services financiers | Données bancaires et financières | 0,95 | 10 |
| Développement et tests | Préset léger pour les environnements de développement | 0,70 | 5 |
| Européen multilingue | Support multilingue pour les marchés de l'UE | 0,85 | 9 |
Présets personnalisés
Créez vos propres présets dans Paramètres → Présets. Sélectionnez les types d'entités, définissez les opérateurs et configurez les seuils de confiance. Les présets personnalisés sont stockés dans votre coffre-fort.
Entités personnalisées
Définissez vos propres types d'entités DPI en utilisant des motifs d'expression régulière. Les entités personnalisées sont détectées aux côtés des types intégrés lors de l'anonymisation.
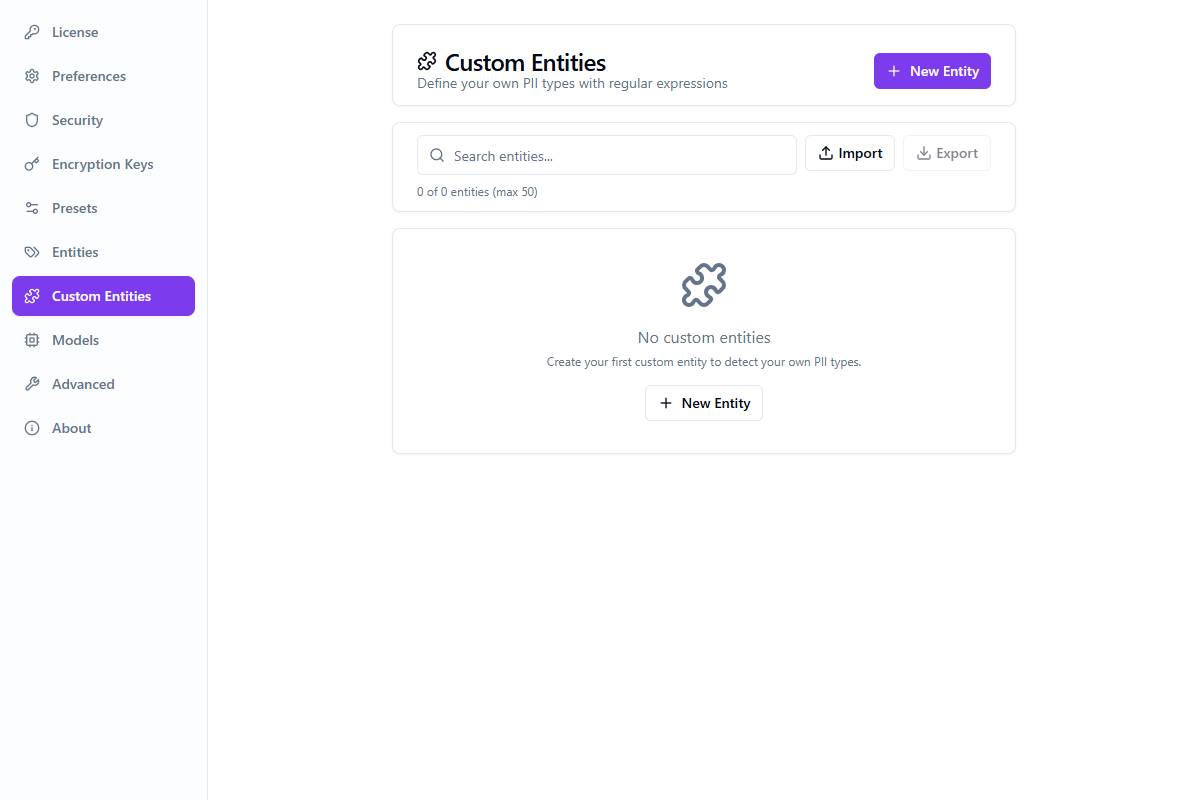
Créer une entité personnalisée
Naviguez vers l'onglet Entités personnalisées dans Paramètres
Cliquez sur « Ajouter une entité personnalisée » et fournissez un nom et un motif regex
Utilisez le testeur de motif intégré pour vérifier les correspondances avec un surlignage en temps réel
Enregistrez l'entité — elle est maintenant disponible dans tous les présets et analyses
Directives de motif
- Utilisez la syntaxe standard de regex JavaScript (aucun délimiteur nécessaire)
- Les motifs sont validés pour la sécurité ReDoS — les motifs de rétroaction catastrophique sont rejetés
- Testez avec des données d'échantillon réelles à l'aide du testeur intégré avant d'enregistrer
- Utilisez des groupes nommés
(?<value>...)pour capturer uniquement la partie pertinente d'une correspondance
Importation et exportation
Les définitions d'entités personnalisées peuvent être exportées en JSON et importées sur une autre machine ou partagées avec les membres de l'équipe. Cela facilite la normalisation des règles de détection dans une organisation.
Limites
| Paramètre | Limite |
|---|---|
| Entités personnalisées maximales | 50 |
| Longueur du motif | 500 caractères |
| Protection ReDoS | Activée — les motifs non sûrs sont rejetés |
Clés de chiffrement
Gérez les clés de chiffrement pour l'anonymisation réversible.
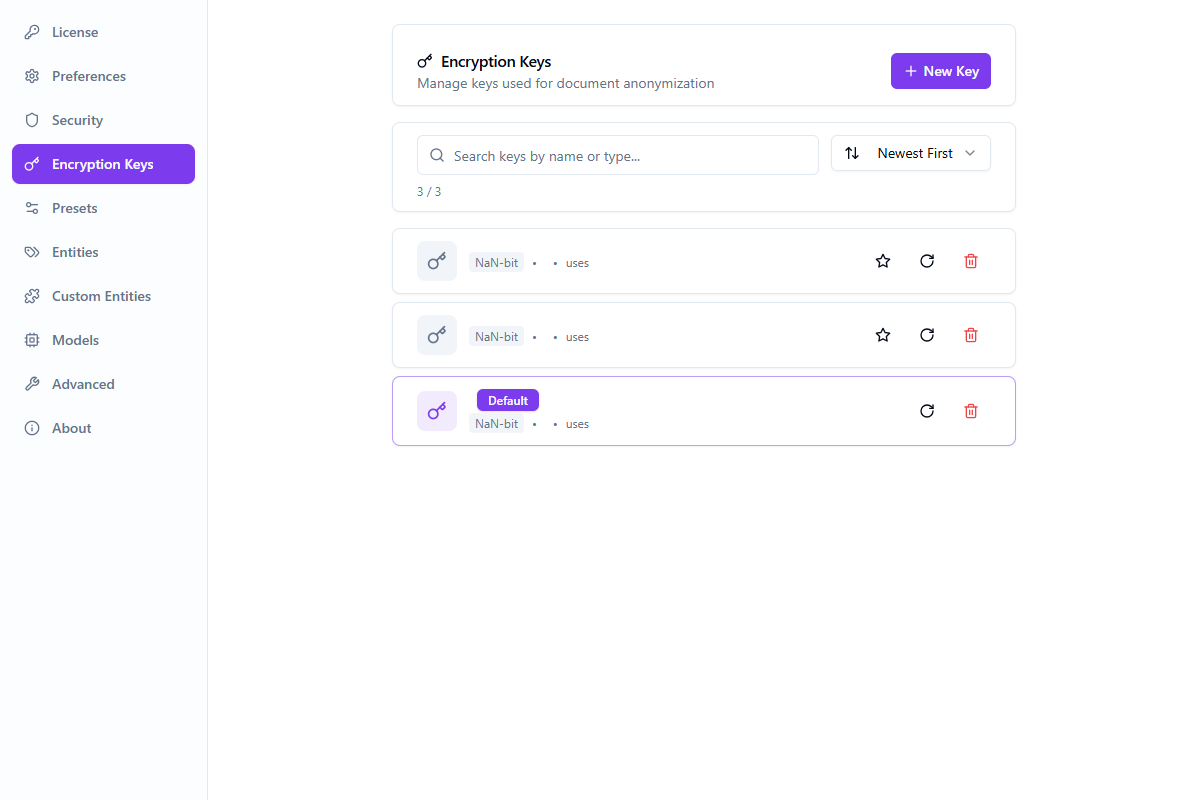
- Créez et stockez les clés de chiffrement de manière sécurisée dans votre coffre-fort
- Appliquez le chiffrement à des types d'entités spécifiques
- Les clés sont stockées localement — seul vous pouvez déchiffrer
- Synchronisez les clés sur les appareils via votre compte
Comment utiliser
Historique de traitement
Affichage et gestion de votre historique d'anonymisation.
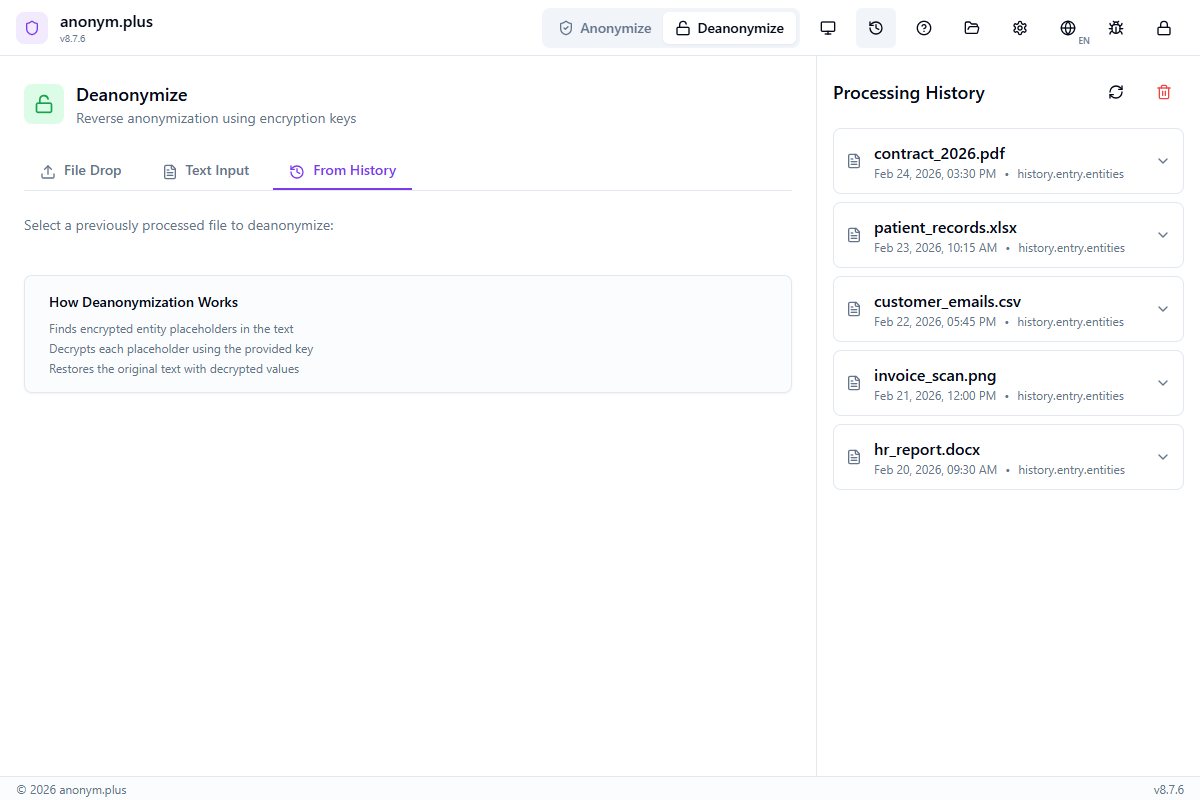
- Affichage de tous les fichiers traités avec horodatages
- Consultez les nombres d'entités et les jetons utilisés
- Copiez le texte d'origine ou anonymisé
- Utilisez les entrées d'historique pour la désanonymisation
- Historique stocké localement dans le coffre-fort chiffré
Paramètres
Compte
- Connectez-vous avec navigateur ou authentification ZK
- Affichage du plan de licence et du statut d'activation
- Synchronisez les présets et les clés de chiffrement
- Déconnexion
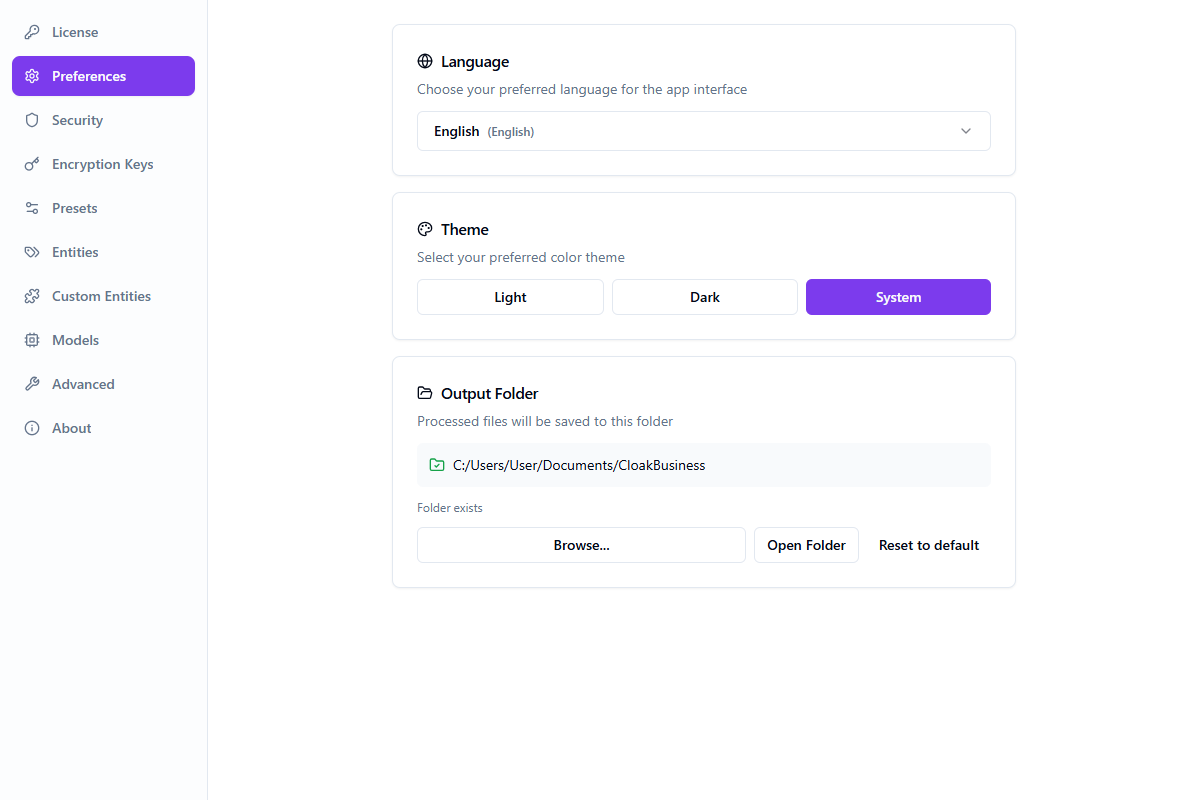
Préférences
- Sélection de la langue (48 langues)
- Thème (Clair / Sombre / Système)
- Configuration du dossier de sortie
- Paramètres de mise à jour automatique
Sécurité
- Modifier ou définir le PIN (4 à 8 chiffres)
- Affichage de la phrase de récupération
- Paramètres de verrouillage du coffre-fort
- Réinitialisation du coffre-fort
Clés de chiffrement
- Créez et gérez les clés de chiffrement
- Définissez la clé par défaut et la liaison du type d'entité
- Rotation des valeurs de clé (affichage unique)
- Les clés sont stockées localement dans le coffre-fort chiffré — les valeurs ne quittent jamais votre machine
Présets
- 121 présets intégrés répartis sur 7 catégories
- Créez des présets personnalisés avec sélection d'entités
- Configurez les opérateurs par type d'entité
- Définissez le préset par défaut pour la sélection automatique
- Dupliquez les présets intégrés en tant que personnalisés
Entités
- Activez/désactivez 200+ types d'entités DPI à l'échelle mondiale
- Recherche et filtrage par groupe d'entités
- Par groupe et boutons globaux Activer tout / Désactiver tout
Entités personnalisées
- Définissez des types de DPI personnalisés avec des motifs regex
- Testeur de motif intégré avec surlignage en temps réel
- Importation/exportation des définitions d'entités personnalisées
- Max 50 entités personnalisées, validation sécurisée ReDoS
Modèles
- Téléchargez des modèles de langue supplémentaires pour la détection de DPI
- 23 langues basées sur spaCy disponibles
- Vérifiez les mises à jour du modèle
- Supprimez les modèles inutilisés pour économiser l'espace disque
Avancé
- Visionneuse de journal de débogage intégrée avec diffusion de journal sur plusieurs fenêtres
- Configuration du niveau de journal
- Gestion des données : exportation, importation, suppression, déplacement des données du coffre-fort
À propos
- Version de l'application et informations de build
- État du moteur (moteur de détection de DPI)
- Téléchargement et installation des mises à jour
- Liens vers la documentation et le support
Raccourcis clavier
| Raccourci | Action |
|---|---|
| F1 | Ouvrir le panneau d'aide |
| Ctrl + , | Ouvrir les paramètres |
| Ctrl + O | Ouvrir un fichier |
| Ctrl + H | Basculer le panneau d'historique |
| Ctrl + Maj + D | Basculer la fenêtre du journal de débogage |
| Échap | Fermer les panneaux |
Sécurité
Chiffrement du coffre-fort
Vos données sensibles sont protégées par un chiffrement de qualité militaire.
- Chiffrement AES-256-GCM pour toutes les données stockées
- Dérivation de clé Argon2id (64 Mo de mémoire, 3 itérations)
- Phrase de récupération BIP39 de 24 mots
- Déverrouillage rapide basé sur le PIN pour l'utilisation quotidienne
- Données sensibles supprimées de la mémoire lorsque verrouillées
Comment vos données sont traitées
Ce que nous ne stockons jamais
Dépannage
| Problème | Solution |
|---|---|
| L'application affiche un écran blanc | Essayez de redémarrer l'application. Si le problème persiste, réinitialisez le coffre-fort dans Paramètres > Sécurité. |
| PIN oublié | Utilisez votre phrase de récupération de 24 mots pour réinitialiser le coffre-fort. |
| Phrase de récupération perdue | Si le coffre-fort est déverrouillé, visualisez-la dans Paramètres > Sécurité. Sinon, les données ne peuvent pas être récupérées. |
| Les fichiers ne se traitent pas | Vérifiez les limites de taille de fichier. Assurez-vous que le format de fichier correct est utilisé. |
| La connexion avec le navigateur ne fonctionne pas | Assurez-vous que votre navigateur par défaut autorise le protocole anonym-plus://. |
| Les présets ne se chargent pas | Vérifiez la connexion Internet. L'application utilisera les présets de secours hors ligne. |
| L'analyse d'image ne retourne aucune entité | Vérifiez que la langue OCR correcte est sélectionnée. Assurez-vous que le texte est clair et lisible à 300+ PPP. Utilisez des captures d'écran plutôt que des photos d'écran. |
| La rédaction d'image manque du texte | L'OCR peut avoir des difficultés avec le texte manuscrit, les très petites polices, le texte déformé ou les arrière-plans complexes. Redressez l'image et augmentez le contraste. |
| Le téléchargement d'image échoue | Vérifiez : format supporté (PNG, JPG, BMP, TIFF), inférieur à 10 Mo, inférieur à 25 mégapixels. |
| « Aucune entité anonymisée trouvée » | Le texte ne contient pas de marqueurs d'entités. Correspond automatiquement à l'historique ou sélectionnez dans l'onglet « Depuis l'historique ». |
| « Le déchiffrement a échoué » | Assurez-vous d'utiliser la même clé de chiffrement de l'anonymisation. Vérifiez dans Paramètres → Clés de chiffrement. |
| Le moteur de détection de DPI ne s'exécute pas | Vérifiez l'état du moteur dans Paramètres → À propos. Cliquez sur redémarrer. Vérifiez le journal de débogage (Ctrl+Maj+D). |
| Les entités personnalisées ne sont pas détectées | Assurez-vous que l'entité est activée dans Paramètres → Entités personnalisées et que le motif regex correspond. |
Messages d'erreur
| Message | Signification |
|---|---|
Aucun contenu de texte trouvé | Le fichier semble être vide ou contient uniquement des images. |
L'analyse a échoué | Assurez-vous que le moteur de détection de DPI est en cours d'exécution. Vérifiez Paramètres → À propos. |
Données d'extraction non trouvées | Le fichier doit être réanalysé. |
Image trop grande | Dépasse la limite de 10 Mo ou 25 mégapixels. Redimensionnez avant le téléchargement. |
Aucun texte détecté dans l'image | L'OCR n'a pas pu extraire de texte. Assurez-vous d'avoir un texte imprimé lisible avec un contraste suffisant. |
Aucune entité anonymisée trouvée | Le texte ne contient pas d'espaces réservés d'entités ou de morceaux chiffrés. Sélectionnez dans l'onglet Historique. |
Le déchiffrement a échoué | Décalage de clé de chiffrement. Vérifiez la clé correcte dans la liste déroulante. |
Les clés de chiffrement ne sont pas trouvées | Les clés doivent être réimportées. Allez à Paramètres → Clés de chiffrement. |
Questions fréquemment posées
Aller à : Sécurité · Anonymisation · Désanonymisation · Clés de chiffrement · Lots · Présets · Entités personnalisées · Images · Modèles · Historique · Licences · Mises à jour · Dépannage
Support
Besoin d'aide ? Contactez-nous par l'un de ces canaux :
- Documentation — cette page
- Contacter le support — soumettre une demande de support
- Signalement de bug dans l'application — utilisez l'icône de bug dans l'en-tête de l'application pour signaler les problèmes avec les informations de diagnostic